It strikes me that developers in JS community tend to choose patterns for solving recurring problems over abstractions.
If we are not busy with semicolon debates, we argue about widely used “callback pattern” for dealing with asynchronous API. Many have learned / invented ways to avoid “pyramids of doom”, but I believe they miss the point: pyramids are not the issue, it’s an indication that we have one.
In order to describe what I consider to be a real issues, I have to move back a little first:
Function
In mathematics, a function is a relation between a set of inputs and a set of potential outputs with the property that each input is related to exactly one output.
Black box
In science and engineering, a “black box” abstraction is used to model systems as set of components which can be viewed solely in terms of its input, output and transfer characteristics, without any knowledge of its internal workings. This components are opaque (black) boxes.

Bigger boxes can be created out of smaller ones just by describing a data flow with in them (connecting inputs and outputs):
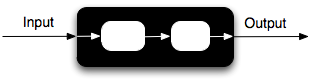
This allows one to reduce details as necessary and change internal implementation of any box without affecting other parts of the system as long as transfer characteristics remain same.
Functions in JS
In programing functions are modeled around the same concepts, even though we
messed up an input sets by adding implicit parts that may change over time.
In JS function input set consists of:
- Given arguments.
- Pseudo-variable
this. - Scope bindings.
Problems
1. No output
Since functions in JS are first class, they can be part of both input and
output sets. Most of the asynchronous APIs take advantage of this fact and
require special callback function argument for continuation passing:
#!/bin/javascript
require('fs').open(path, 'r+', function(error, fd) {
// ...
})
As you can see such functions no longer have have any useful output, which means that they can’t be used for building systems as black boxes. Such functions don’t return values that can be passed over to other boxes.
2. Error handling on each step
I have heard many times people criticizing how in Java exceptions are caught, wrapped and re-thrown again. This reminds me of following:
#!/bin/javascript
function readJSON(path, callback) {
fs.readFile(path, function(error, content) {
if (error) callback(error);
else callback(null, JSON.parse(content));
})
}
Basically error propagation in “callback” style APIs is done manually. Note,
that in some cases you may want to try catch actual function body as well.
3. Polygamy
It easy to end up with two types of functions: synchronous and asynchronous. While it’s possible to make sync function async it’s not the case other way round. This usually means that if one the functions had being converted to be asynchronous all of it’s users will have to be converted as well:
#!/bin/javascript
function readJSON(path) {
var data = fs.readFileSync(path)
return JSON.parse(String(data))
}
You can’t simply switch to readFile if becomes necessary.
4. Progress tracking
Finally if your function depends on multiple asynchronous inputs then you will have to manually track each.
#!/bin/javascript
function makeView(templateURI, dataURI, callback) {
var template, data, pending = 2
readURI(templateURI, function(error, content) {
if (error) return callback(error)
template = content
if (!--pending) Mustache.render(template, data)
})
readURI(dataURI, function(error, content) {
if (error) return callback(error)
data = content
if (!--pending) Mustache.render(template, data)
})
}
Also note that this code assumes that readURI will call a callback only once,
which is not guaranteed.
Describe logic not mechanics
Now consider our last example. Most of the code there is for handling mechanics rather than describing a logic, which feels absolutely very wrong. As a matter of fact actual logic can be expressed as:
#!/bin/javascript
function makeView(templateURI, dataURI) {
var template = readURI(templateURI)
var data = readURI(dataURI)
return Mustache.render(template, data)
}
So, would not it be better to abstract timing out of logic when it’s not necessary rather than keep solving all this issues in each and every function ? As a mater of fact solution has being there for ages in a form of promises, but for some reason people and web standards tend to use callbacks instead. Maybe because they feel complicated, but that does not necessary has to be the case:
#!/bin/javascript
// Everyone knows how to write a function:
function sum(a, b) { return a + b }
console.log(sum(1, 2)) // => 3
// Working with promises should not require nothing more
// than marker telling that function can accept input in
// form of promises
sum = promised(sum)
console.log = promised(console.log)
// Will continue to work with plain old values
console.log(sum(1, 2)) // => 3
// Will also accept promises as arguments
var deferred = defer() // make promise
var a = deferred.promise
var b = sum(a, 1)
var c = sum(b, 5)
console.log(c) // eventually prints => 17
deferred.resolve(11) // fulfill promise
We should not be handling and propagating exceptions manually in each function, we should only handle them when we plan to recover:
#!/bin/javascript
// Utility funciton that throws exceptions
var raise = promised(function(_) { throw Error(_) })
var a = raise('Boom !') // Now we got an exception
var b = sum(a, 2) // Now it has propagated to b
var c = sum(b, 12) // Now it has propagaed to c
// Finally if when ready we handle exception in computation
c.then(null, console.error) // => Error: Boom !
If we just want to group multiple values into one there is an Array for that
no need to track progress of each eventual value if we just care about a group!
#!/bin/javascript
Array = promised(Array)
var results = Array(readAsync(a), readAsync(b))
console.log(sum.apply(sum, rusults))
Noticed a pattern ? We just write a logic, and if it needs to handle
asynchronous input we wrap it into promised(logic).
Whats really important here is that such functions can be used to build systems
in black boxes, since they do have input and output. Demonstration of
that is an example from above (assuming that readURI returns promise):
#!/bin/javascript
function makeView(templateURI, dataURI) {
var template = readURI(templateURI)
var data = readURI(dataURI)
// Assuming Mustache.render = promised(Mustache.render)
return Mustache.render(template, data)
}
Implementing such a solution takes about 100 lines of code (ignoring comments), and that’s more or less what any other control flow library costs anyway. I wish all of you to have more time to concentrate on logic of your program instead of mechanics & small promise library may be a good first step!